
Un point auquel nous ne faisons par suffisamment attention en référencement naturel… C’est la duplication de contenu. Oui, ce petit critère SEO qui nous paraît à première vue anodin et qui pourtant, peut ruiner la visibilité de divers business ou sites e-commerce. Mais alors, comment vérifier le duplicate content sur son site web et qu’est-ce que cela signifie exactement ?
Comme tu le sais probablement, le duplicate content consiste à copier-coller un contenu pré-existant et déjà indexé sur les moteurs de recherche. Ça paraît hyper basique au départ et peu gênant.
Mais le problème, c’est que le but des moteurs de recherche étant de fournir aux internautes le meilleur contenu possible… Comment savoir lequel mettre en avant quand ils sont tous similaires ?
Forcément… Ça peut nous pénaliser.
Les 2 types de duplicate content en SEO
Ce qu’il faut savoir, c’est qu’il existe plusieurs types de duplicate content. Un que l’on maîtrise à 100% et un second qui sera disons… Beaucoup plus compliqué à gérer pour son site web ! ?
- Duplicate Content Interne : Il arrive très fréquemment que deux pages web venant d’un seul et même site web contiennent chacune exactement le même contenu. Et ce, que ce soit au niveau des balises title, meta-description ou bien du texte en lui même. Réalisé de façon intentionnel ou sans même s’en rendre comptes, ça peut très rapidement devenir néfaste pour ton site web.
- Duplicate Content Externe : Ce type de duplicate content est quant à lui, plus délicat. Et oui, car celui-ci arrive lorsqu’un autre site web copie-colle ton propre contenu. Cela peut-être par exemple sous-forme de plagiat ou bien via un site partenaire qui reprend la description de l’un de tes produits. C’est plutôt compliqué à gérer, mais il existe une solution que l’on retrouvera ci-dessous avec la balise canonical. ?
5 Causes communes de duplicate content interne
Il est fort possible que sans t’en rendre compte, ton site web est bourré de duplicate content interne. Et cela arrive généralement toujours pour les mêmes raisons qui sont généralement :
• Paramètre URL : Même si indispensable, intégrer des paramètres dans une URL génère du duplicate content ex: «https://www.monsiteweb.com?parametre=1¶metre=2». (les UTMs Google Analytics, en font notamment parties)
• Fiches produits similaires : Il arrive couramment de vendre un même produit aux caractéristiques proches (ex:couleurs), et de réaliser une fiche produit très similaire pour chacune de ces caractéristiques. Obligatoirement, cela entraîne un fort taux de duplicate content.
• Tags : Intégrer des tags dans ses articles de blog est une fausse bonne idée. Et oui, car à force de compléter chacun de ses articles avec des tags très proches les uns des autres, on fini par créer des pages de tags menant à des résultats similaires… Hello duplicate content !
• Balise title & meta-description : Ah ces fameuses balises… Malheureusement, lorsque l’on ne s’y connaît pas suffisamment et que l’on ne gère pas à 100% le développement de son site web… Il arrive souvent de se retrouver avec des balises non optimisées ou dupliquées entre elles ou bien entre plusieurs pages.
• Nom de domaine : Qu’est-ce que je veux dire par nom de domaine ? Parfois, une même page de votre site peut être accessible via différentes URL. Comme notamment http – https ou encore avec et sans www. Une grande cause de duplicate content…
Voilà, tu as un petit aperçu de quelques aspects du web qui peuvent causer du duplicate content… Maintenant, let’s go découvrir comment gérer son duplicate content et avec quels outils !
6 Outils pour vérifier le duplicate content de son site web
Bien heureusement, il existe de nombreux outils qui nous permettent d’analyser et gérer son duplicate content. Généralement payant, tu en retrouveras tout de même quelques uns gratuits et hyper utiles au quotidien pour optimiser son référencement naturel. ?
- Screaming Frog SEO : Un outil indispensable dans le quotidien d’un référenceur, Screaming Frog SEO est un outil gratuit qui te permettra d’analyser la présence de balises dupliquées.
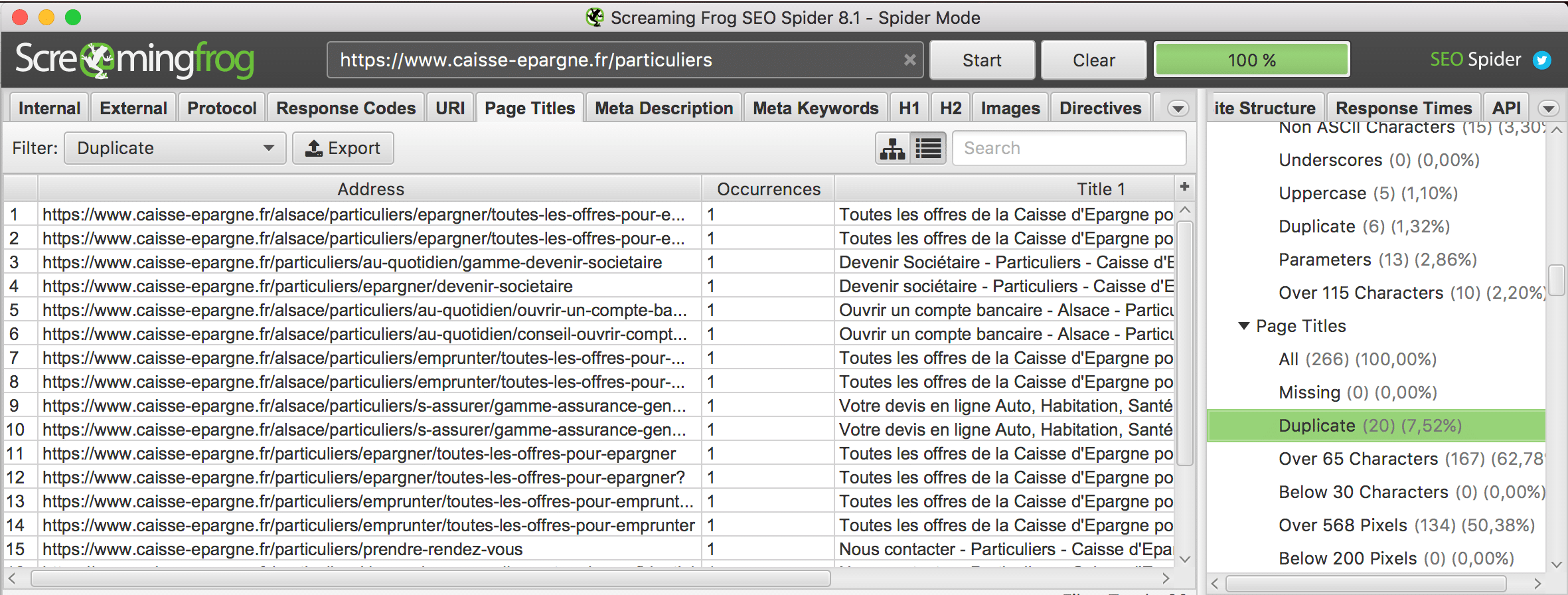
- Google Search Console : Lorsque tu te rends sur Google Search Console, tu remarqueras qu’il y a une petite section «Amélioration HTML». Et bien celle-ci t’indiquera très rapidement si tu as des balises title ou meta-description dupliqué sur ton site web… Discret, mais bien pratique ! ?
- Google : Et oui, ça peut paraître étonnant mais une simple recherche avancée Google avec l’aide crochets » « , peut nous permettre de savoir si un contenu apparaît de manière identique sur d’autres pages externes ou internes.
- Positeo : Un petit outil qui permet d’identifier si un contenu en particulier a été dupliqué ou non, et sur quels sites web.
- KillDuplicate : À tester prochainement, KillDuplicate semble être un outil très sympa pour analyser et gérer rapidement le duplicate content de son site web.
- Copyscape : Simple mais pratique, Copyscape permet d’analyser une page web afin de vérifier s’il existe ou non, du duplicate content sur celle-ci.
Alors, c’est bien pratique ces outils mais comment faire pour éviter d’être pénalisé quand je dois réaliser du contenu obligatoirement dupliqué, ou qu’un site externe copie-colle mon contenu ?
Et bien voici une petite solution ! ?
Comment éviter d’être pénalisé par des URLs obligatoirement «dupliquées» ?
Si dans ta situation actuelle, il t’est indispensable de créer des pages dupliquées… Pas de panique. Par exemple, imaginons que tu vends une chemise de 5 couleurs différentes et qu’une fiche produit a été créée pour chacune des couleurs. Sachant que le texte et quasi-totalement similaire, cela va créer du duplicate content.
Mauvais, mauvais pour ton référencement !
Alors pour éviter ça, il te suffira simplement de sélectionner la fiche produit qui te semble être la plus pertinente et devrait être correctement indexée sur les moteurs de recherche. (Ici ce sera la chemise blanche par exemple)
Une fois ceci fait, il ne te restera plus qu’à intégrer une balise nommée «canonical» dans le header des autres pages ayant du contenu dupliqué. Comme ceci :
<link rel= »canonical » href= »https://www.url-principale-a-indexer » />
Cette balise dira simplement à Google de ne pas indexer ces pages contenant du contenu dupliqué. Et ce, afin de ne pas pénaliser l’URL canonique principale qui est ici, la fiche produit de la chemise blanche.
Et voilà, le tour est joué ! ??
P.S : Attention, pensez aussi à mettre en place des redirections 301 quand nécéssaire et notamment entre les différents formats d’URL de nom de domaine ! (ex: avec www. et sans www.)


Bonjour,
Positeo n’existe plus ?
C’est pourtant encore d’actualité, malheureusement, en 2019, malgré toute cette prévention !!!!
excellent article sur le problème du duplicate content
L’outil de Positeo est nickel, je recommande. Simple et gratuit en plus..
merci pour les autres ressources !
Bonjour,
Merci pour vos conseils. Google, à mon avis, devrait voir uniquement la date de la publication et non pas la notoriété du site. Car seule la date prime. Sauf bien sur si on peut trafiquer la date de publication. Mais dans tous les cas, c’est mort si quelqu’un copie ton contenu.
Bonjour et merci pour ces conseils. Dites-moi, si un ou plusieurs sites copient les fiches produits, comment faire? Changer, les envoyer des emails pour dire qu’ils ont copié? autres suggestions?
Hello 🙂
À ma connaissance, Google prend en compte la date de publication ainsi que la popularité du site web pour déterminer quelle page indexer. Alors si tes fiches produit ont été rédigées avant que les autres sites les plagient et qu’ils ont une popularité largement inférieure… Tes pages devraient être indexées sans problème.
Mais oui, malheureusement dans le cas contraire il va falloir les contacter afin de leur demander de supprimer le contenu ou bien (si c’est un partenaire par exemple) d’ajouter une balise canonical sur la page dupliquée.